Overview
Avoiding congestion before it occurs is a proactive approach to improving network performance. As a flow control mechanism, congestion avoidance actively monitors network resources (such as queues and memory buffers), and drops packets when congestion is expected to occur or deteriorate.
Compared with end-to-end flow control, this flow control mechanism controls the load of more flows in a device. When dropping packets from a source end, it cooperates with the flow control mechanism (such as TCP flow control) at the source end to regulate the network traffic size. The combination of the local packet drop policy and the source-end flow control mechanism helps maximize throughput and network use efficiency and minimize packet loss and delay.
Tail drop
Congestion management techniques drop all packets arriving at a full queue. This tail drop mechanism results in global TCP synchronization. If packets from multiple TCP connections are dropped, these TCP connections go into the state of congestion avoidance and slow start to reduce traffic, but traffic peak occurs later. Consequently, the network traffic jitters all the time.
RED and WRED
You can use random early detection (RED) or weighted random early detection (WRED) to avoid global TCP synchronization.
Both RED and WRED avoid global TCP synchronization by randomly dropping packets. When the sending rates of some TCP sessions slow down after their packets are dropped, other TCP sessions remain at high sending rates. Link bandwidth is efficiently used because TCP sessions at high sending rates always exist.
The RED or WRED algorithm sets an upper threshold and lower threshold for each queue, and processes the packets in a queue as follows:
When the queue size is shorter than the lower threshold, no packet is dropped.
When the queue size reaches the upper threshold, all subsequent packets are dropped.
When the queue size is between the lower threshold and the upper threshold, the received packets are dropped at random. The drop probability in a queue increases along with the queue size under the maximum drop probability.
WRED uses differentiated drop policies for different IP precedence values. Packets with a lower IP precedence are more likely to be dropped.
If the current queue size is compared with the upper threshold and lower threshold to determine the drop policy, bursty traffic is not fairly treated. To solve this problem, WRED compares the average queue size with the upper threshold and lower threshold to determine the drop probability.
The average queue size reflects the queue size change trend but is not sensitive to bursty queue size changes, and bursty traffic can be fairly treated. The average queue size is calculated using the following formula: average queue size = previous average queue size × (1-2-n) + current queue size × 2-n, where n can be configured with the qos wred weighting-constant command.
With WFQ queuing used, you can set the exponent for average queue size calculation, upper threshold, lower threshold, and drop probability for packets with different precedence values to provide differentiated drop policies.
With FIFO queuing, PQ, or CQ used, you can set the exponent for average queue size calculation, upper threshold, lower threshold, and drop probability for each queue to provide differentiated drop policies for different classes of packets.
Relationship between WRED and queuing mechanisms
Figure 22: Relationship between WRED and queuing mechanisms
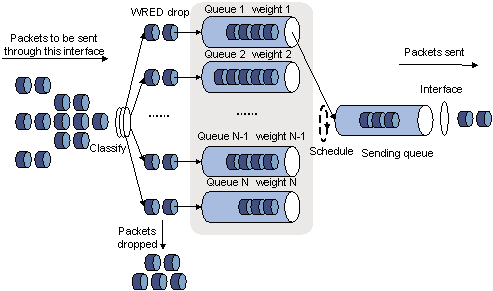
Through combining WRED with WFQ, the flow-based WRED can be realized. Because each flow has its own queue after classification, a flow with a smaller queue size has a lower packet drop probability, when a flow with a larger queue size has a higher packet drop probability. In this way, the benefits of the flow with a smaller queue size are protected.